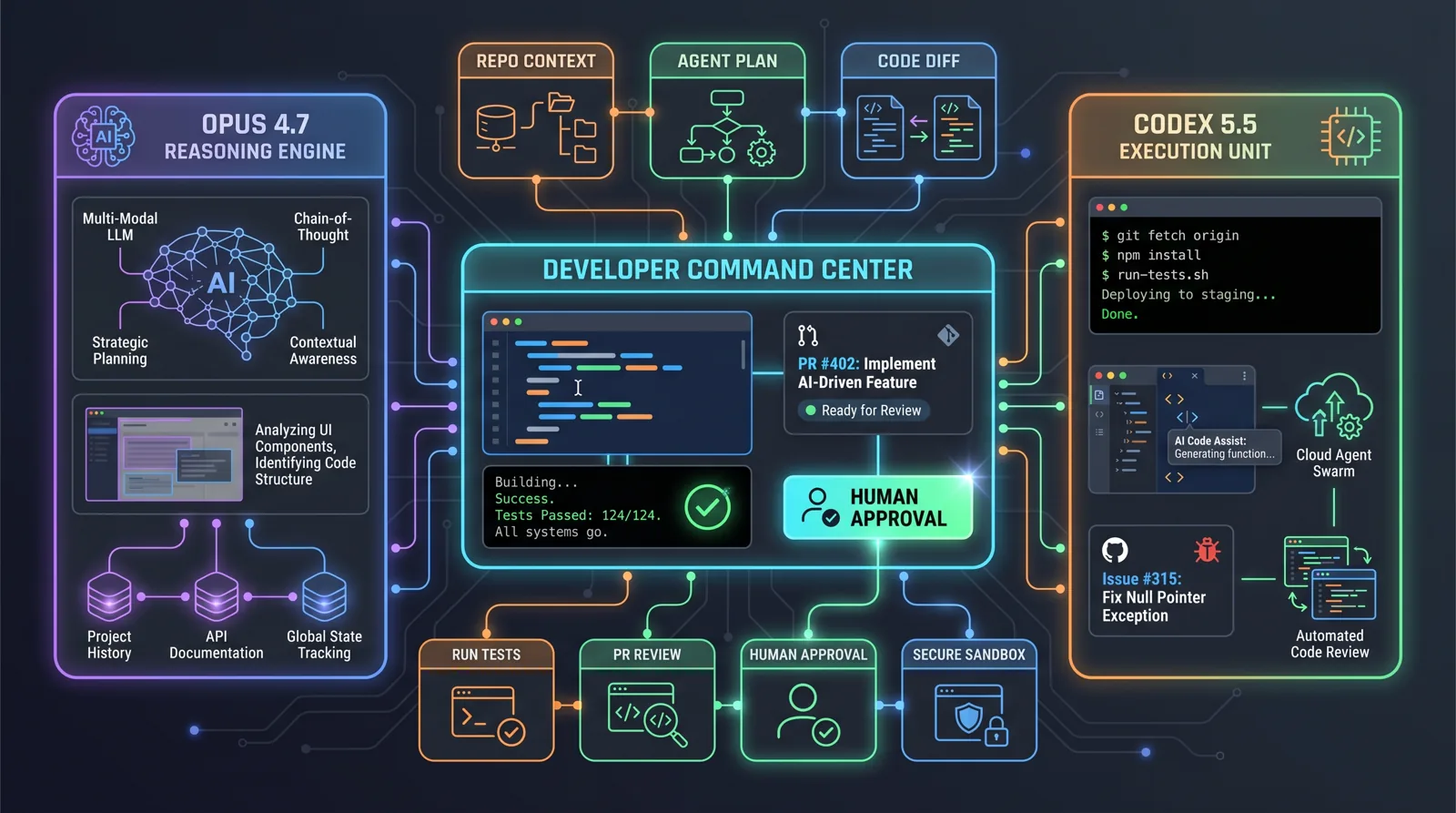
Claude Opus 4.7 vs. Codex 5.5 for Business
Claude Opus 4.7 and GPT-5.5 in Codex move AI coding agents forward. What changes for companies, where to use them, and how to stay in control.

Vít Šafařík
AI & business productivity
When someone says “AI programmer” today, many people still imagine a smarter autocomplete. That view is already outdated. Claude Opus 4.7 and GPT-5.5 in Codex point in a different direction: an agent that receives a work package, a repository, tests and boundaries — and tries to deliver a finished pull request.
For a company, this does not mean firing developers tomorrow. It means something more practical: part of the work that used to wait for a senior engineer or an external agency can now run as a controlled process. A small service refactor. Bug fixes. Test coverage. API migration. Documentation. An internal tool. And most importantly: everything through Git, build, tests and human approval.
This is not about “which model is best”. It is about the type of work
Claude Opus 4.7 and GPT-5.5 in Codex both target long, tool-heavy, multi-step work. Still, it is better to think beyond a single benchmark leaderboard.
Claude Opus 4.7 is positioned by Anthropic for complex reasoning and agentic coding tasks. Three things matter in practice: better performance on long-running tasks, more precise instruction following, and higher-resolution image support for screenshots and visual work. In the API, the model ID is claude-opus-4-7, with large-context support and mechanisms such as effort and task budgets for agentic runs.
GPT-5.5 in Codex is strong not only as a model, but as a working environment. OpenAI describes it as a model for “messy, multi-part tasks” — work where the system must plan, use tools, check results and continue through ambiguity. The Codex changelog shows that the product around the model is maturing as well: CLI, IDE, cloud, code review, goals, permissions, plugins and integrations.
Translated into business language: Claude often looks strongest as a deep task solver. Codex is strong as a work system around a repository. In practice, the actual outcome still depends on the task, the codebase, tests and the approval workflow.
What actually changes for companies
The biggest change is not faster code generation. The biggest change is that AI agents are getting better at a longer loop:
- understand the task,
- inspect the existing codebase,
- propose changes,
- modify multiple files,
- run tests or a build,
- fix failures,
- prepare a diff for review.
This is exactly the kind of work that often gets stuck inside companies. Not because it is impossible, but because nobody has capacity. Typical examples include:
- old internal scripts without tests,
- a broken CRM-to-invoicing integration,
- manual reporting across five systems,
- an admin dashboard everyone wants but nobody schedules,
- technical debt in an e-commerce or B2B portal,
- migration from one API to another.
Before, these items became backlog. Now they can become a queue of agentic work packages. Each task has a clear brief, branch, test, pull request and a human reviewer.
Where I would use Claude Opus 4.7
Claude Opus 4.7 makes sense where deeper reasoning and less linear work are required.
Typical situations:
- untangling a complex bug report,
- proposing a refactor before implementation,
- working with a larger amount of context,
- analysing architecture and dependencies,
- rewriting business logic where meaning matters more than syntax,
- reviewing a larger proposal or pull request,
- working with screenshots, diagrams, documents and UI references.
A particularly important detail in Opus 4.7 is more precise instruction following. That is good news, but also a risk. If you have an old prompt like “fix it somehow and be concise”, the new model may take it too literally — or expose that the instruction was poorly written in the first place. For agents, you need a clear operating system:
- what it may change,
- what it must not change,
- when to run tests,
- when to stop,
- how to report uncertainty,
- which files are sensitive.
A stronger model will not save a bad process. It will only execute it faster.
Where I would use GPT-5.5 in Codex
I would use GPT-5.5 in Codex where the workflow around the repository matters most.
Typical situations:
- fixing GitHub issues,
- small to medium feature branches,
- generating tests,
- maintaining documentation in the repo,
- bulk mechanical changes with validation,
- work in CLI or IDE,
- code review workflows.
Codex is interesting because it is not “just a model”. It is an environment for working with code: sandboxing, permissions, goals, integrations and the ability to run in the CLI, IDE and cloud. For companies, that matters because governance is not only a prompt. Governance is also where the agent runs, what permissions it has, what files it sees and who approves the result.
Without process, it is just more expensive chaos
For both directions, the same rule applies: agentic coding without boundaries is a risk.
The most common mistake I see is giving the agent a task that is too broad. “Go through our system and improve it.” That is not a task. That is an invitation to a random diff.
A better task looks like this:
Goal: add CSV export for accounting.
Scope: backend endpoint + button in admin.
Do not change: invoicing logic, payment module, authentication.
Validation: npm test, npm run build, manual CSV check on 3 samples.
Output: pull request with changes and risks.This does not turn AI into a magician. It turns AI into labour inside a defined process.
A practical deployment model
For a smaller company, I would not start with “Claude or Codex?”. I would start here:
- Pick one safe backlog type. Documentation, tests, an internal report, a simple admin feature.
- Give the agent only a repo and a branch. Not the production database. Not full cloud access.
- Require build and tests. Without validation, the PR is not done.
- Approve through pull requests. The agent must not merge by itself.
- Measure the real outcome. How many tasks passed review? How many were discarded? How much time was saved?
Only after that does it make sense to add more advanced orchestration: multiple agents, parallel research, automatic issue triage or internal system integrations.
What to watch next
Claude Opus 4.7 and GPT-5.5 both show that coding agents are moving from “write me a function” toward “complete this work package”. That is a big difference.
For companies, four questions will matter most:
- Reliability: does the agent finish consistently, or only occasionally shine?
- Cost: is a frontier model worth it for this task, or is a cheaper model plus better process enough?
- Control: can you limit permissions, data and scope?
- Integration: does the agent fit into GitHub, Slack, Telegram, CI and the existing workflow?
My view: the winner will not be the model with the nicest demo. The winner will be the company that treats agentic development as a process change. Small, safe tasks. Clear boundaries. Automatic validation. Human approval.
If you want to find out where agentic development would make sense in your company, start with an AI audit. We will review your backlog, internal processes and technical risks, then select the first automation with real return. If you already know what you want to try, reach out through contact.
Share this article
Found this article helpful? Share it with colleagues who might benefit.